PostgreSQL HA DR Cycle¶
Overview¶
PostgreSQL HA DR Cycle shows the higher-control recovery path in the platform. The primary estate stays on-prem, recovery is rebuilt into GCP from pgBackRest, a fresh backup is pinned from the recovered cluster, and service returns on-prem through a controlled failback path.
It suits teams that want repeatable recovery proof, direct control over the database estate, and evidence that service can return cleanly.
Case study¶
- Context: the on-prem PostgreSQL HA estate needed current public proof of a full recovery cycle rather than older run records alone.
- Challenge: the platform had to prove restore into GCP, backup continuity from the recovered lane, and controlled return on-prem without relying on stale runtime state.
- Approach: pgBackRest object storage remained the recovery backbone.
dr/postgresql-ha-failover-gcp@v1drove restore into GCP, a fresh backup was taken from the recovered cluster, anddr/postgresql-ha-failback-onprem@v1handled the controlled return. - Outcome: the March 31, 2026 redrill restored the service into GCP on
10.72.16.23, pinned backup set20260331-173211F, returned service on-prem on10.12.0.31, and retained the full run record set.
The evidence below captures recovery into GCP, fresh backup continuity, controlled return on-prem, and final DNS truth after failback.
Covers pgBackRest restore into GCP, fresh backup from the recovered cluster, controlled failback on-prem, and final DNS truth after the full cycle.
Outcome¶
This recovery path proves database recovery, not just infrastructure recreation.
- Recovery into GCP is driven from the backup and restore chain, not from assumptions about standby readiness.
- A fresh backup is pinned from the recovered GCP cluster before failback begins.
- Service returns on-prem through a deliberate path with final DNS truth preserved.
Operating model¶
- The primary service is a self-managed on-prem PostgreSQL HA estate.
- pgBackRest object storage is the recovery backbone.
- GCP is used as the recovery environment for the drill.
- Return on-prem is a planned step, not an implicit side effect.
Compared with the managed Cloud SQL path, this option keeps more database control and architectural symmetry at the cost of higher operational involvement.
The recorded redrill covers the full path from on-prem primary to GCP recovery and back again, with Patroni state, backup continuity, and final service position treated as part of the result.
Architecture¶

The recovery route is driven from the backup chain, not from assumptions about standby readiness. The GCP lane is backed up again before service returns on-prem.
Recovery sequence¶
- The on-prem source and recovery repository are prepared and verified.
- PostgreSQL is restored into the GCP recovery environment.
- Patroni state and DNS cutover confirm the recovered GCP service position.
- A fresh GCP backup is taken from the recovered primary.
- Service returns on-prem and DNS truth is checked after failback.
| Stage | Run started | State published | Elapsed |
|---|---|---|---|
| Restore to GCP | 2026-03-31T17:03:59Z |
2026-03-31T17:30:57Z |
26 min 58 sec |
| Fresh GCP backup | 2026-03-31T17:31:52Z |
2026-03-31T17:32:19Z |
27 sec |
| Failback to on-prem | 2026-03-31T17:34:58Z |
2026-03-31T17:44:36Z |
9 min 38 sec |
The March 31, 2026 timings reflect the recorded redrill path that restored into GCP, pinned a fresh backup, and returned service on-prem.
Platform state¶
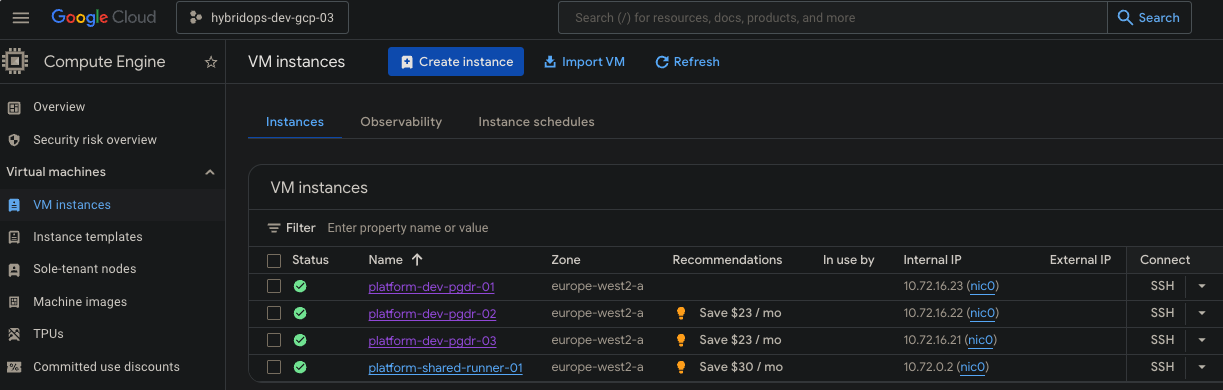
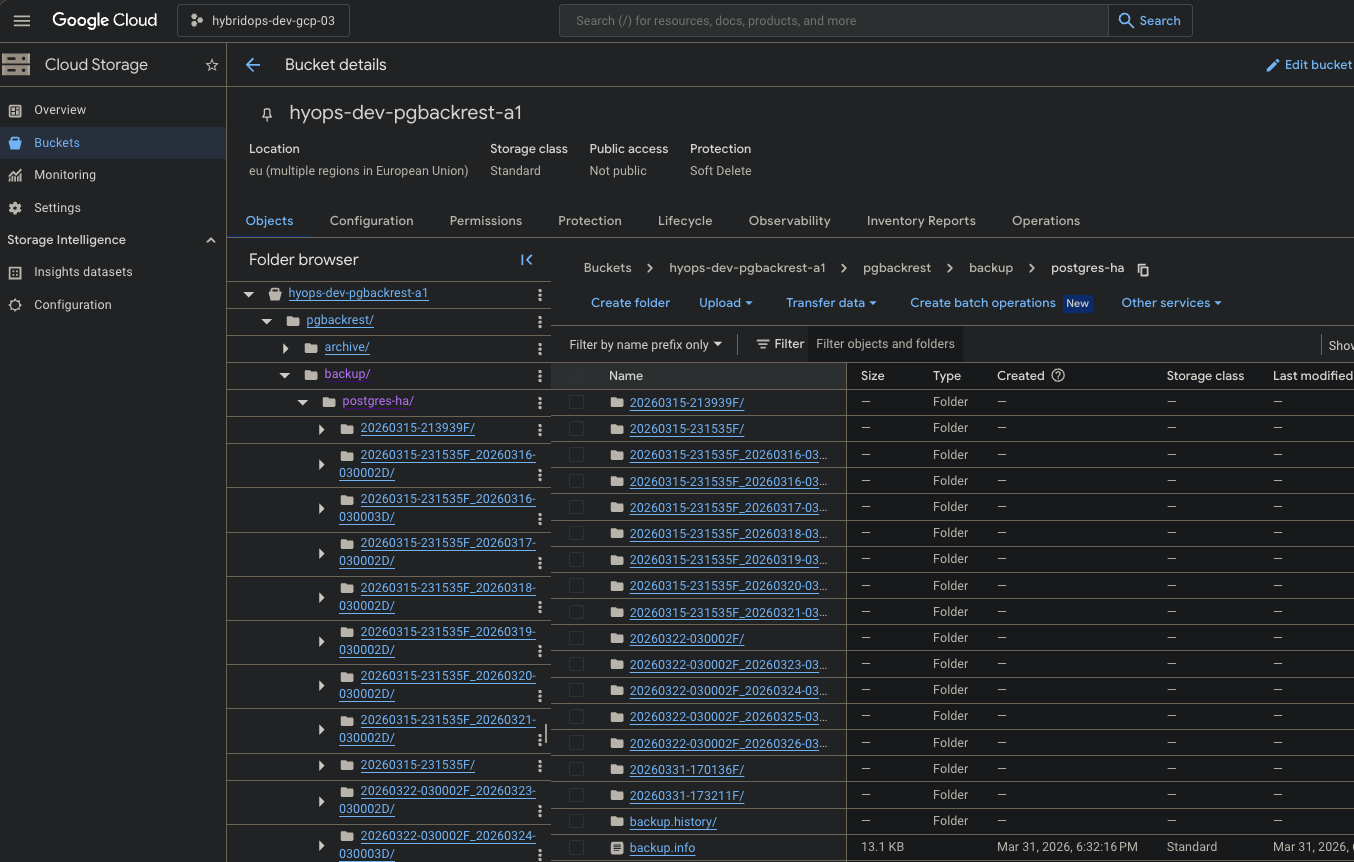

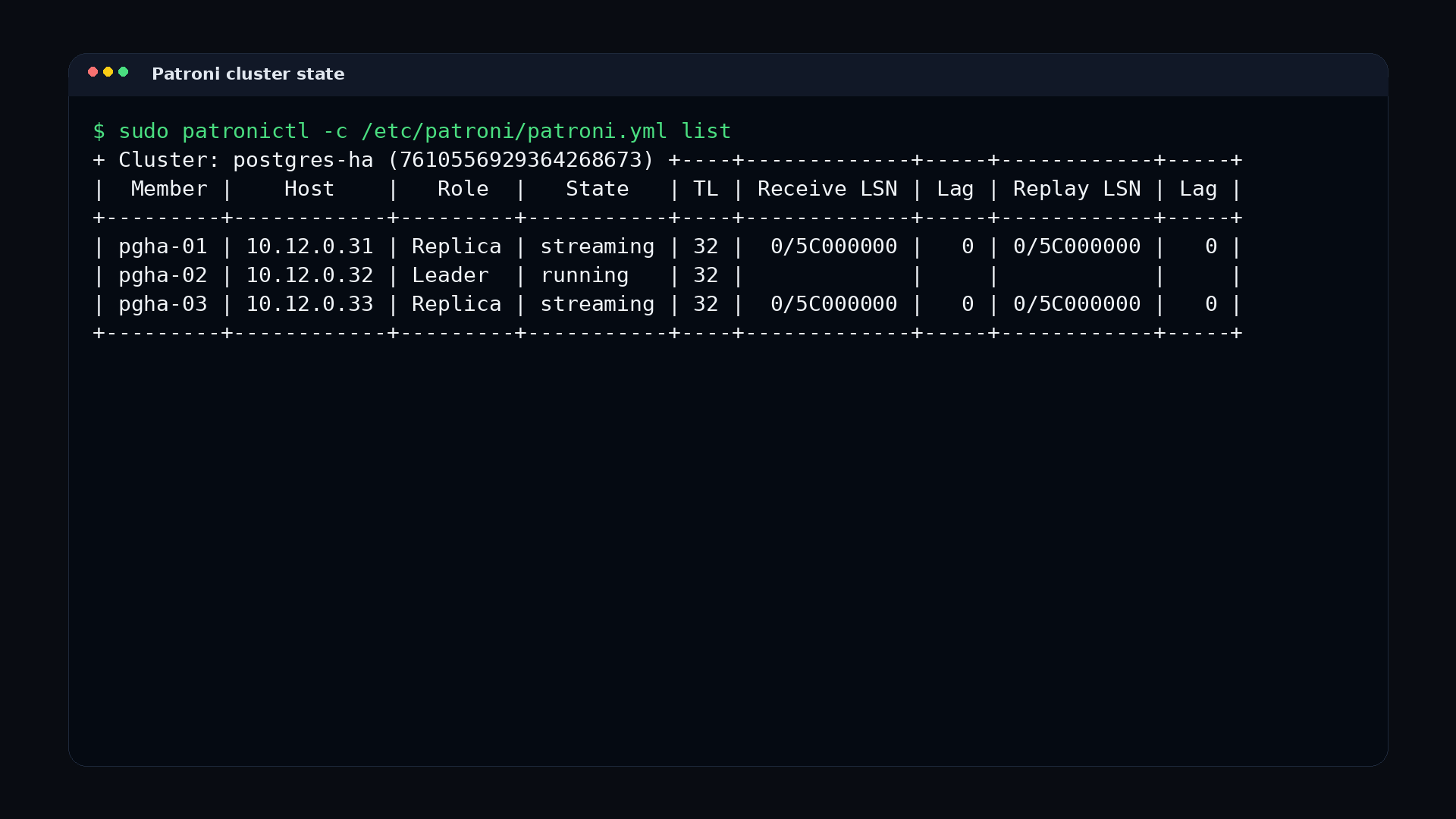
IP addresses, hostnames, and instance identifiers visible in screenshots and recordings reflect the ephemeral infrastructure provisioned during the recorded exercise.
Implementation¶
- Recovery backbone: pgBackRest object storage drives restore into GCP; recovery is from the backup chain, not from a standby assumption.
- Failover path:
dr/postgresql-ha-failover-gcp@v1restores the cluster into GCP and validates Patroni state and DNS position. - Backup continuity: a fresh backup is taken from the recovered GCP primary before any failback begins.
- Failback path:
dr/postgresql-ha-failback-onprem@v1returns service on-prem with DNS cutover as a final controlled step. - DNS layer:
platform/network/dns-routingmanages the cutover record across both directions.
Where it fits¶
- when the database platform itself is part of the protected service
- when recovery proof, cluster health, and final DNS truth matter as much as rebuild speed
- when architectural symmetry matters more than minimising ongoing database operations
Key components¶
- Primary blueprint:
onprem/postgresql-ha@v1 - Failover blueprint:
dr/postgresql-ha-failover-gcp@v1 - Failback blueprint:
dr/postgresql-ha-failback-onprem@v1 - Recovery backbone: pgBackRest object storage
- Continuity step: fresh GCP backup before failback
- DNS cutover layer:
platform/network/dns-routing
References¶
Further reading
Implementation references
platform/postgresql-haplatform/postgresql-ha-backupplatform/network/dns-routingorg/gcp/object-repo#pgbackrest_primary
Related¶
Related reading¶
- Failover PostgreSQL HA to GCP (HyOps Blueprint)
- Failback PostgreSQL HA to On-Prem (HyOps Blueprint)
- Repeatable PostgreSQL App-Data DR Validation Drill
- Cleanup the PostgreSQL App-Data DR Validation Lanes
What was verified¶
Verified during the recorded March 31, 2026 self-managed PostgreSQL HA redrill, including GCP restore, fresh backup continuity, on-prem failback, Patroni streaming confirmation, and final DNS truth.